Scaling Self-Play
New scaling laws may be on the horizon – R1 and o3 are RL-trained by letting the models learn via self play. Why is this possible now? And what does this mean for the future of model capabilities?
The o3 / R1 releases just confirmed that with a sufficiently clear reward signal, models unlock emerging capabilities like reasoning.
To recap, we know that R1 optimises a policy that rewards:
- Accuracy: e.g. maths problems checked by proof assistants or code verified by compilers.
- Formatting: e.g. using specific tags (e.g.,
<think>and<answer>) that lead to responses with higher “ratings”. The policy learns when it is appropriate to<think>, which one could argue translates to some awareness of its own uncertainty.
This is fantastic news for maths and programming. I predict that models will become very spikey in these abilities. Any verifiable task that lives in symbolic space will drastically improve beyond human capabilities. It might be the case that because maths is so detached from our evolutionary process, humans are actually quite bad at it relative to what is possible.
Programmers, I have a bit more hope for. They continuously interact with the real world (customers) to re-define their problems – so until models can approximate (human) theory of mind and emulate what the customer wants, programmers should be fine – their jobs will just shift in the abstraction stack of logic. Also, see Jevons paradox: we may see a lot more demand for software engineers.
But even for tasks that are tricky to specify rewards for, I am hopeful. We may be reaching a point where models become self-improving.2
I predict this will look something like...
Sam Altman: Here is a paragraph. One of our guys in the basement labled this as a great paragraph compared to these other paragraphs. Do you understand why this is so great?
Model_1 (set to high Temperature): Hmm yes, because of the nuanced use of X and Y...
Sam Altman: Models_2345, do you agree?
Models_2345: Yes, Yes, No, Yes
Group Relative Policy Optimization: I have now learned a bit more about what makes a great paragraph
US Gov: Sam you can't just put people in basements and make them label things.
Sam Altman: Model_1, can you just start generating your own questions and verify them with your friends?
This sounds suspicous. How can a model generate new information in a vaccuum? Why won't it just start making stuff up? Well, this is the answer:
\mathcal{J}_{\text{GRPO}}(\theta) = \mathbb{E} \bigg[ \frac{1}{G} \sum_{i=1}^G \bigg( \min \bigg( \frac{\pi_\theta(o_i|q)}{\pi_{\theta_\text{old}}(o_i|q)} A_i, \, \text{clip}\bigg(\frac{\pi_\theta(o_i|q)}{\pi_{\theta_\text{old}}(o_i|q)}, 1-\epsilon, 1+\epsilon \bigg) A_i \bigg) - \beta D_\text{KL}(\pi_\theta \| \pi_\text{ref}) \bigg) \bigg]
This is GRPO. It's the recipe for what we did above: we count the votes of our friends to tell us by how much, and in what direction, to update our model weights. We penalise the policy, \pi_\theta – unlike in PPO, the model here itself is the policy – when it:
- Updates too quickly from the previous policy, \pi_{\theta_\text{old}}
- Deviates too far from the pre-trained policy, \pi_\text{ref}
- Generate plausible explanations, which may not have emerged explicitly or strongly enough from the training distribution
- Verify those explanations by generalising from the "ground-truth" pre-training
- Reinforce those explanations by updating its policy. This "patches" up areas where the training distribution is sparse in data, but are still compatible/generalise from the pretraining
(please send me papers to confirm my biases! :)
If you find this interesting, here are some more thoughts on why reasoning might work very well. Firstly, it should be noted that the structure of reasoning these models exhibit wasn't explicitly forced onto them. It emerges naturally. My guess is that what PPO is doing is telling the model: here is a query from your pretraining, and here is a response, also from your pretraining. You can assume these are true. Find the lowest energy path (reasoning) between these, across the pretraining landscape. Now let's reinforce this path so that you don't have to even think about it anymore. i.e. pay energy on MC sampling so that you can do System 2 thinking, and move it into System 1. So my bet is that pretraining contains sufficiently expressive representations to do this.
---
If this is true, then we might be entering a second paradigm of training. Unlike pretraining, researchers will be more intentional with what knowledge/capabilities they want to patch into their models – destroying benchmarks go brr brr. I have no idea what the economics of this will look like – clearly some training directions will have more diminishing returns (e.g. real-world spatial understanding, where the pretraining might be too sparse), while others will have instant economic incentives to throw compute at. A lot of money will be invested here on test-time.3
This will loosen Nvidia's grip on the market ever-so-slightly...
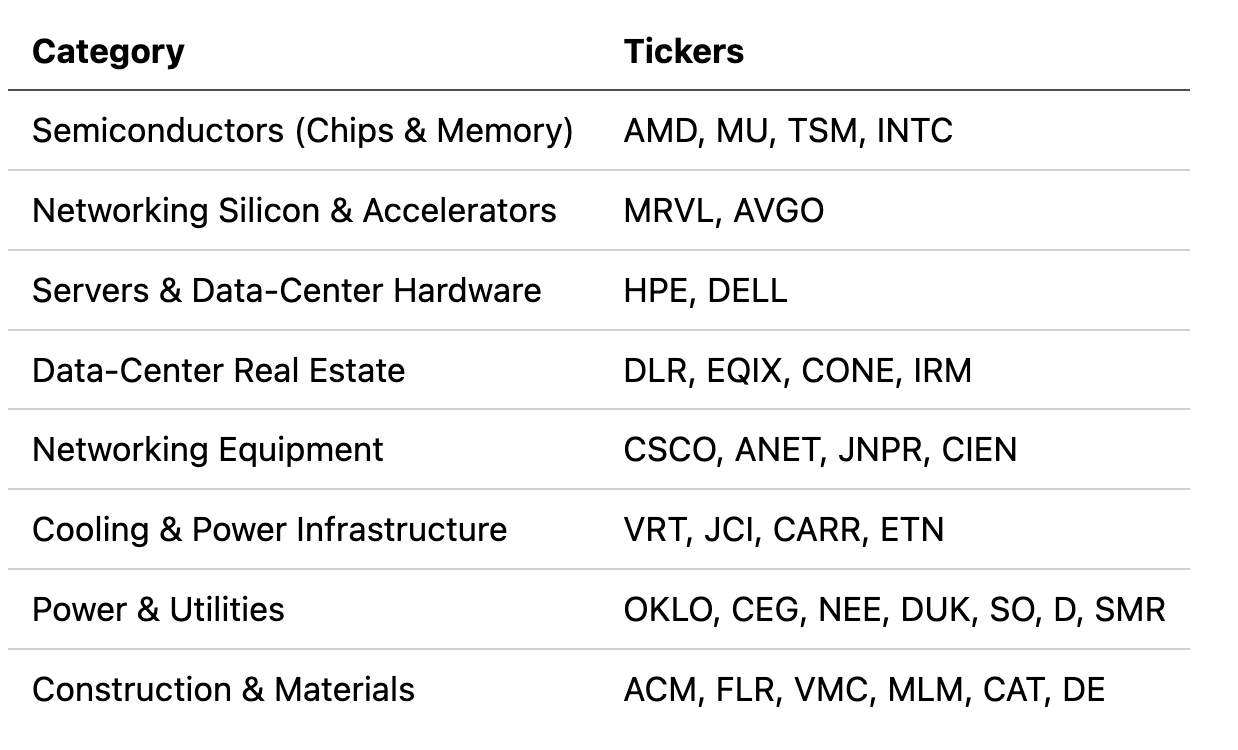
Inference models (e.g. Groq) require less high-bandwidth memory (i.e. moving weights between VRAM and CPU). Nvidia is very good at this – to the extent that buying an Nvidia GPU is less expensive than getting an AMD GPU for free and paying for its energy costs. The point is, this will be less of a bottleneck in inference chips, so others can compete harder. I also want to add that this is not financial advice... here is a list of companies that stand to benefit from scaling data-centres:
---
The field of potential avenues for reasoning models is wide open. I think there will be a lot of new approaches coming out of this – it’s hard to make predictions. But if you forced me to give one example it would be along the lines reasoning in a continuous latent space.4 This might make test-time compute more efficient. And maybe maths should be done in a separate symbolic space within the model etc. etc.
If this new paradigm is to translate to the real world, then we will need to find ways to pretrain models on new data as well. Although models can learn things without “experiencing” them, e.g. gaining spatial awareness from text only, this seems to have diminishing returns. My guess is that “real-world” pretraining of current models does not have enough expressiveness/representations to do the kind of test-time reasoning that we see in abstract space with R1. The bottleneck will be to bring the external world to the model: feed more images, videos, let the model interact with the world, etc. My prediction is that we will start caring a lot more about this: the most important advancements in the next few years will be new architectures/data-generation/compression techniques for the real-world.5 Maybe to be give a hypothetical example:
- Figuring out how to avoid feeding entire images into CLIP, and instead feeding high entropy areas/representations, to reduce computation
- Instead of feeding a video as series of images, instead we feed some entropy delta between each frame
(these are made up on the spot – I have no idea what I am talking about. I just quite like the idea of entropy)